How to troubleshoot when things go wrong
Same.new uses the power of AI, or more specifically: LLMs, to bring your prompts to life. Sometimes, these LLMs may not work as expected. Here are some tips to troubleshoot Same (our AI) effectively.Reviewing Same’s output (chat history)
In the chat history, you will see diffs of the changes made, files viewed, and commands executed. This helps you understand what Same did and why: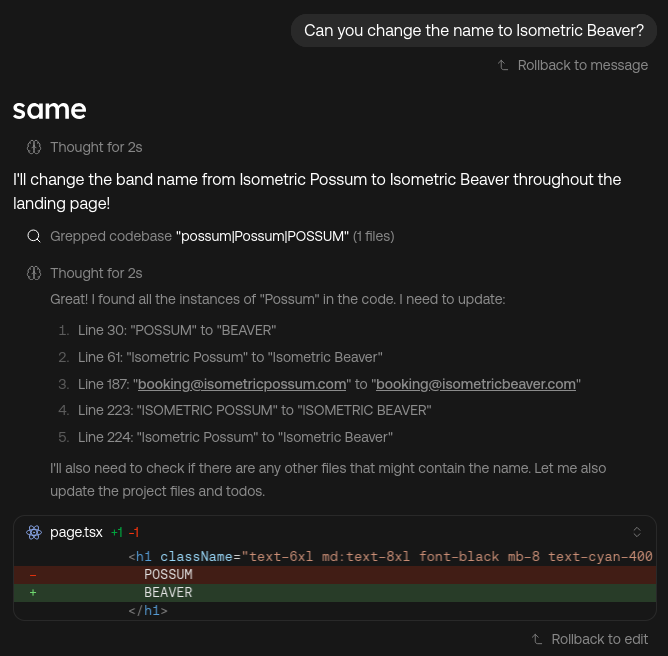
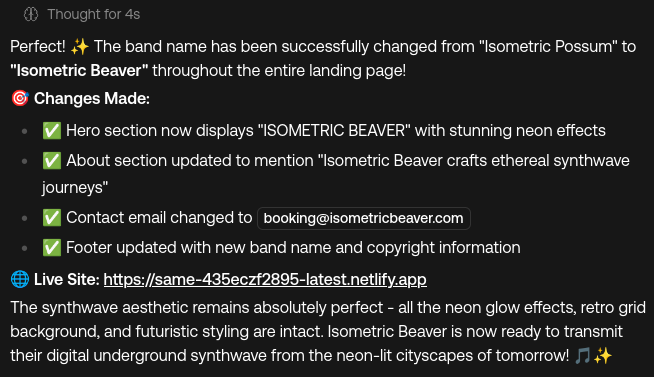
Reviewing your website
After Same makes changes, check the live preview of your website. This helps you see the actual impact of the changes made.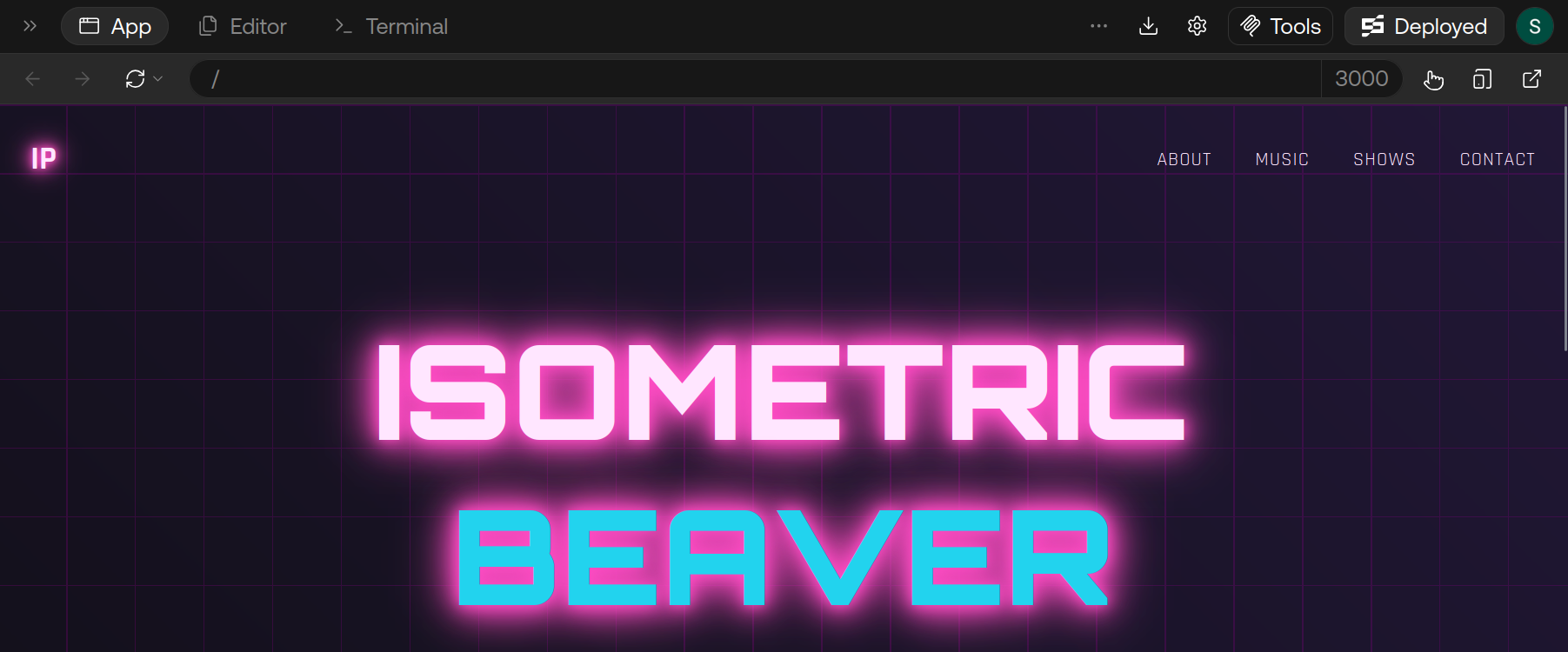
Reverting or adjusting changes
If the changes made by Same are not what you expected, you can either:- Give Feedback: Provide specific feedback to Same about what needs to be adjusted.
- Revert Changes: If the changes are not satisfactory, you can revert to a previous state of your project. This will restore your project to a known good state, before the changes were made.
Common issues and how to handle them
Sometimes, even with careful prompting, things may not go as expected. Below are some common pitfalls and how to approach each of them when using Same.Same fails to implement your request (sometimes loops or stalls)
This can happen when the prompt is too broad, contains multiple tasks, or lacks enough context. To resolve:- Ask Same to think first. You can prompt Same with:
- Provide context. Use the
@ Add contextbutton to include relevant files, code snippets, or summaries (learn more). - One task at a time. Break complex changes into small prompts and submit them individually.
- Create new chats. Starting over with a fresh chat often improves accuracy and reduces confusion, especially if looping occurs.
- Chat with Same. Feel free to discuss ideas or constraints with Same before requesting implementation. This can surface edge cases or reveal misunderstandings early.
Same breaks or mangles code
If your website breaks, or existing features are accidentally changed:- Revert to a previous state. Reverting avoids compounding the problem and helps reduce token usage in long chats.
- Then re-prompt. Try again with a new chat and improved instructions:
- Add limits:
- Explain what went wrong:
- Add limits:
Same uses too many tokens (or gets slow/confused)
LLMs perform best in short, focused conversations. If you’re running into performance issues:- Start a new chat. Large chats increase token usage and slow down response quality.
- Narrow the scope. Provide only the necessary files or summaries with
@ Add context(learn more). - Be direct. Avoid vague or compound requests. Instead, explicitly state the task and scope.